The R-CNNs are awesome works on object detection, which demonstrated the effectiveness of using region proposals with deep neural networks, and have become a state-of-the-art baseline for the object detection task. In this blog post I'll make a brief review of the R-CNN family - from R-CNN to Mask R-CNN, and several related works based on the idea of R-CNNs. Implementation and evaluation details are not mentioned here. For those details, please refer to the original papers provided in the References section.
0 Object Detection before R-CNN
Before CNN was widely adopted in object detection, SIFT or HOG features are commonly used for the detection task.
Unlike image classification, detection requires localizing objects within an image. Common approaches to localization are 1) bounding box regression, and 2) sliding-window detector. The first approach used in [1] proved to be not working very well, while the second used in [2] needs high spatial resolutions, thus deeper networks makes precise localization a challenge.
1 R-CNN: Region-based R-CNN
R-CNN solves the CNN localization problem by operating the "recognition using regions" paradigm.
Overview
From the input image, the method first generates around 2000 category-independent region proposals with Selective Search algorithm, and then extracts a fixed-length feature vector from each proposal using the same CNN(AlexNet). Finally, it classifies each region with category-specific linear SVMs.
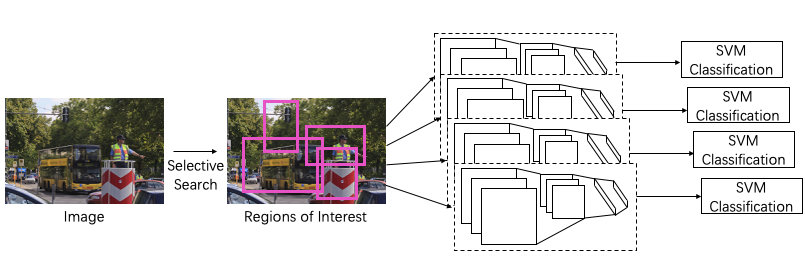
Fig. 1 Overview of R-CNN.
However, the region proposal may not be that satisfactory as a final detection window. Therefore, a bounding-box regression stage is introduced to predict a new detection window given the feature map of a region proposal. As reported in [3], this simple approach fixes a large number of mislocalized detections. More details are available in the supplementary material[12] of the R-CNN paper.
Since AlexNet only takes images of size 227 × 227, the image clip in the bounding box should be resized.
In R-CNN, the image clip is directly warped into the demanded size.

Fig. 2 Cropping from the bounding box and warping.
Contribution
- The region proposal(RoI) - feature extraction - classification approach
- Using Selective Search to generate region proposals
- Using bounding-box regression to refine region proposals
- Using CNN features for classification
Known drawbacks
- Run CNN feature extraction on each of the 2000 regions consumes too much computation
- The warped content may result in unwanted geometric distortion
2 SPP-Net: Spatial Pyramid Pooling
SPP-Net introduces the spatial pyramid pooling layer that takes in feature maps of arbitrary size, while also considering multi-scale features in the input image. It also solved the way-too-slow issue of R-CNN.
Overview
While R-CNN extracts features from warped image clips in each proposed region, the SPP-Net first extracts the feature of the whole image and get one shared feature map. After this, the feature map is cropped according to the bounding boxes (boxes fixed by regressor, same as R-CNN). Each of the feature map clip is put into the spatial pyramid pooling layers to get a feature vector of the same length. Then the feature vectors are the inputs of following fully connected layers which are the same as R-CNN.
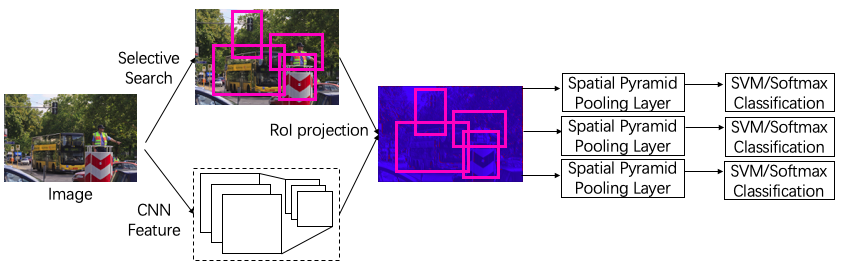
Fig. 3 Overview of SPP-Net.
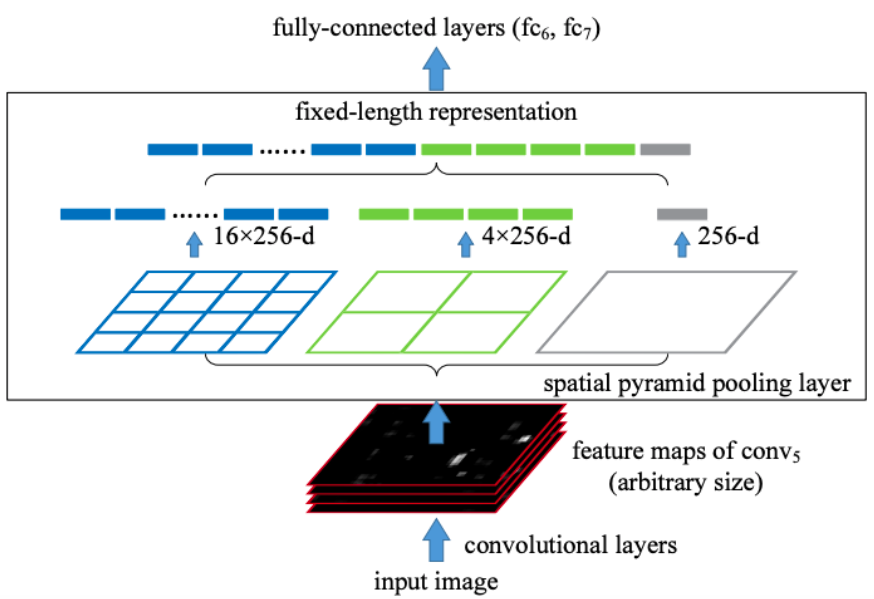
Fig. 4 Spatial pyramid pooling layer.
The spatial pyramid pooling layers consider the feature map clip in different scales - it divides the feature map clip into 4 × 4, 2 × 2 and 1 × 1 grids and computes 4 × 4, 2 × 2 and 1 × 1 feature maps (channel number doesn't change). The computed feature maps are flattened and concatenated into one vector, which is the input of the following fully connected layers.
Contribution
- Extracting feature maps first and only once, greatly improves the speed of R-CNN
- Using spatial pyramid pooling layers, avoiding geometric distortion
Known drawbacks
- Training classifier and box regressor separately requires much work
3 Fast R-CNN: Feature Extraction Only Once
As mentioned in the paper, R-CNN is slow because it performs a ConvNet forward pass for each object proposal, without sharing computation. Fast R-CNN improved its detection efficiency by using the deeper VGG16 network, which is 213 times(nice number :D) faster than R-CNN. It also introduced RoI pooling layer, which is simple a special case of SPP-Net where only one scale is considered(only one pyramid level). Fast R-CNN uses a multi-task loss and is trained in single stage, updating all network layers. Fast R-CNN yields higher detection quality(mAP) than R-CNN and SPP-Net, while being comparatively fast to train and test.
Overview
Similar to SPP-Net, Fast R-CNN extracts image features before the RoI-based projection to share computation and speed up detection. But differently, Fast R-CNN uses a deep neural network - VGG16 for more efficient feature extraction. Rather than training bounding-box regressor and classifier separately, Fast R-CNN uses a streamlined training process and jointly optimize a softmax classifier and a bounding-box regressor. The RoI-fixing regressor is moved after the fully-connected layers. The multi-task loss for each RoI is defined as:
$$L(p,u,t^u,v) = L_{cls}[p,u]+\lambda[u\geq 1]L_{loc}(t^u,v)$$
in which the definition of classification loss and localization loss are:
$$L_{cls}(p,u)=-log(p_u)$$
$$L_{loc}(t^u,v)=\sum_{i\in \{x,y,w,h\}}{smooth_{L_1}(t_i^u-v_i)}$$
in which \(smooth_{L_1}\) loss is defined as:
$$smooth_{L_1}(x)=\begin{cases}
0.5x^2& \text{if |x|<1}\\
|x|-0.5& \text{otherwise}
\end{cases}$$
Symbol definitions:
| Symbol | ||
|---|---|---|
| Output of the classification layer, a vector of length \(K+1\)(K object classes and background) | \(p=(p_0,\cdots,p_K)\) | |
| Output of the regression layer, a matrix of size \(K\times 4\). | \(t^k=(t^k_x,t^k_y,t^k_w,t^k_h)\) | |
| True class. | \(u\in N, 1\le u \le K\) | |
| True bounding-box regression target. | \(v=(v_x,v_y,v_w,v_h)\) |
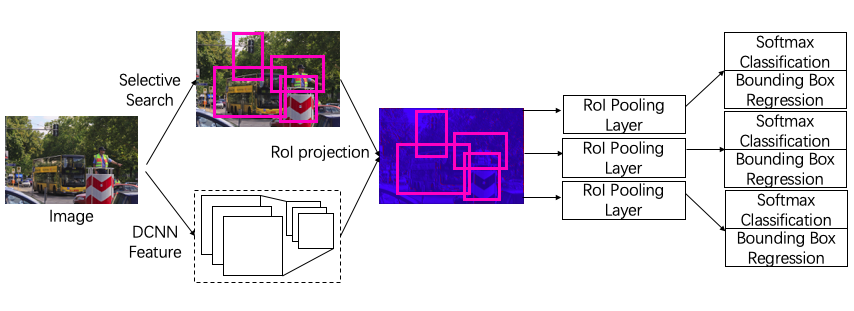
Fig. 5 Overview of Fast R-CNN.
In this architecture, two of the three main procedures except region proposal are trained in single-stage with the multi-task loss.
Here is are two graphs demonstrating common pooling layers(max or avg) and RoI pooling layers. On the left is the original 5x5 feature map, and each in grid is a pixel value. During calculation, the common pooling kernel covers an area each step and calculates the maximum value or the average value in the area. With a kernel size of 3x3 and a stride of 2, a feature map of 2x2 is generated from the 5x5 feature map.
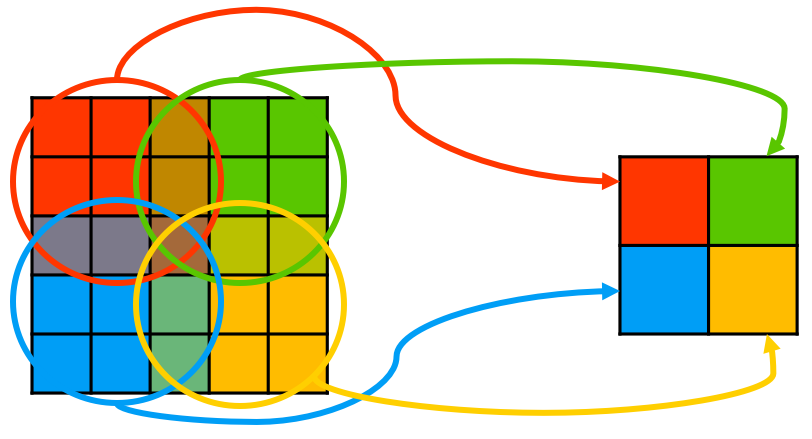
Fig. 6 Common pooling with kernel_size=3 and stride=2.
And in RoI pooling, the RoI is cropped from the whole feature map, and is divided into pieces with equal areas according to the output feature map size. However, it's possible that grids on the borders of different pieces have to be assigned to one piece only. In this case, there may be a little bit of "injustice" among the pieces. In each piece, a global average/maximum pooling is done and the result is only one number in each channel.
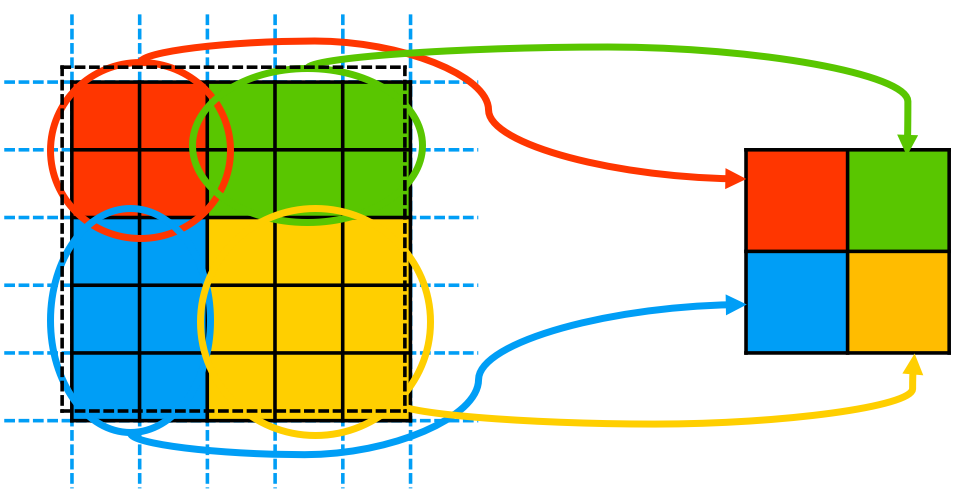
Fig. 7 RoI pooling with output size=(2, 2). The black dashed line denotes the original RoI, and the colored area is the actual cropped RoI.
Contribution
- Deeper CNN - VGG16 for feature extraction
- Multi-task loss & Single-stage training
Known drawbacks
- For region proposal, conventional Selective Search algorithm doesn't make use of GPU computation power, thus consuming more time
4 Faster R-CNN: Region Proposal Networks Speeds You Up
In Fast R-CNN, two of the three main procedures are trained in single-stage, except region proposal. And region proposal is the bottleneck of total detection speed, since GPU with high computation power isn't utilized here yet. Why not try training a CNN that generates region proposals?
Overview
Simply remove the Selective Search in Fast R-CNN. In place of the SS algorithm, an RPN(Region Proposal Network) is introduced. Given the DCNN features, the RPN generates RoIs with improved speed.
...but how on earth does the RPN work?
This is a question that had been confusing me for so long.
In a word, it's a simple CNN taking an image of any size as input, slides a window and outputs \(6k\) numbers each time the window moves. \(k\) is the number of anchors pre-defined - IT DOES NOT MEAN "THOUSAND". Wait, what is an anchor?
An anchor is a box size we define first before generating data (for example, \((width=36, height=78)\) for pedestrain, and \((width=50, height=34)\) for dogs?). Though the input image is of size \(n * n\), the anchor can be in any size and any w-h ratio. The prediction of the 6 numbers are based on the anchors we define. When the RPN works, it does NOT predict the possibility that there is an object - BUT the possibility that there is an object that fits in the anchor.
Besides a classification layer predicting the possibility of there being an object and the possibility of there being nothing but background, a regression layer predicts the relative box coordinates \((t_x, t_y, t_w, t_h)\). For each anchor, its size \((w_a, h_a)\) is given and its position \((w_x, w_y)\) is decided by the center position of the sliding window. The relation between relative coordinates \((t_x, t_y, t_w, t_h)\) and absolute coordinates \((x, y, w, h)\) is:
$$t_x=(x-x_a)/w_a\\
t_y=(y-y_a)/h_a\\
t_w=log(w/w_a)\\
t_h=log(h/h_a)$$
for both prediction and ground truth.
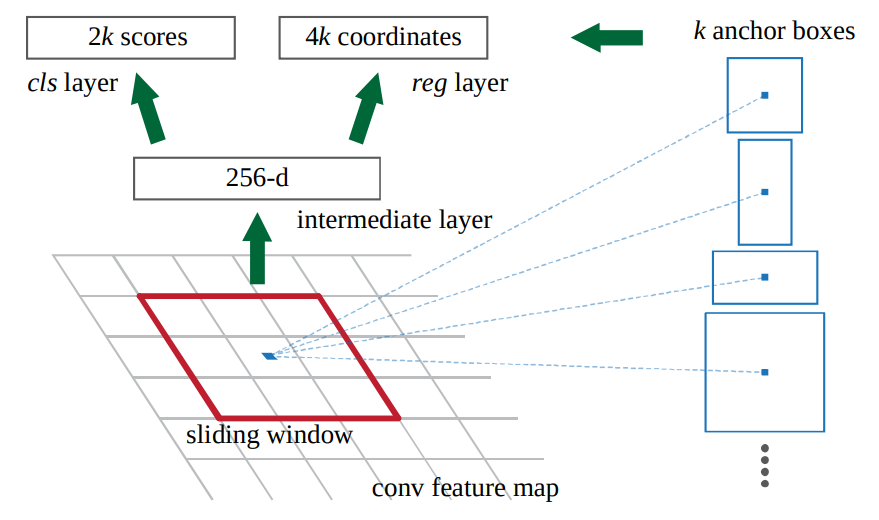
Fig. 8 The original graph demonstration of RPN. Keep in mind that "k" does not mean "thousand".
But there are a great pile of boxes generated by the RPN. Some basic methods have to be taken to select the "good" boxes. Firstly, the boxes with low object scores and high background scores (usually thresholds are set manually) are abandoned. Secondly, using non-maximum supression, one box for each object target is elected from all boxes that mark the same object.
Contribution
- Region Proposal Network - high-speed high-quality region proposals
5 Mask R-CNN: Detection and Instance Segmentation
Though Mask R-CNN is a great work, its idea is rather intuitive - since detection and classification is done, why not add a segmentation head? In this case, some instance-first instance segmentation work would be done!
Overview
Add a small mask fully-convolutional overhead to Faster R-CNN, replace VGG net with more efficient ResNet/FPN(Residual Network / Feature Pyramid Network) and replace RoI pooling with RoI alignment.
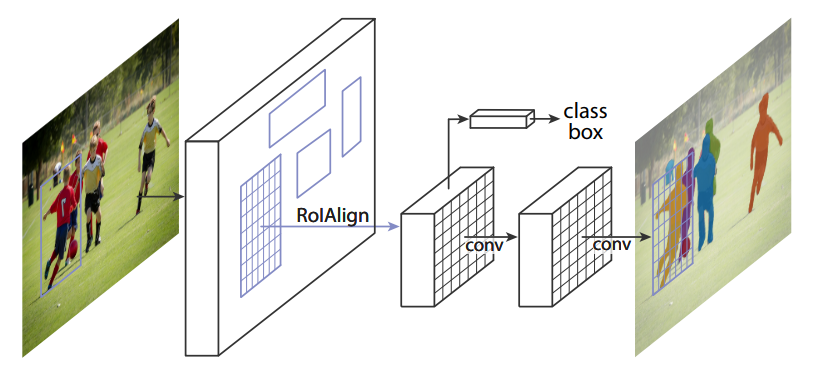
Fig. 9 The Mask R-CNN framework for instance segmentation. The last convlutional layer is the newly added segmentation layer for each RoI.
RoIAlign
In RoI pooling, quantization will be performed when the RoI coordinates are not integers. For example, when cutting the area \((x_1=11.02, y_1=53.9, x_2=16.2, y_2=58.74)\), actually the area \((x_1=11, y_1=54, x_2=16, y_2=59)\) is what we get (nearest-neighbor).
But in RoI alignment, the area is exactly \((x_1=11.02, y_1=53.9, x_2=16.2, y_2=58.74)\). Instead of cropping it down, the feature map area is sampled using some sample points. Divide the RoI into \(n*n\)(output size) bins Using bi-linear interpolation, one value would be calculated at each sample point. In the image below is a simple example. In this case we have only one sample point for each pixel in the pooled RoI. Coordinate of the only sample point in the first area is \((12.315, 55.11)\). Calculate the weighted average of the 4 grid points nearby his sample point and we'll have the value for this pixel in the pooled feature map.
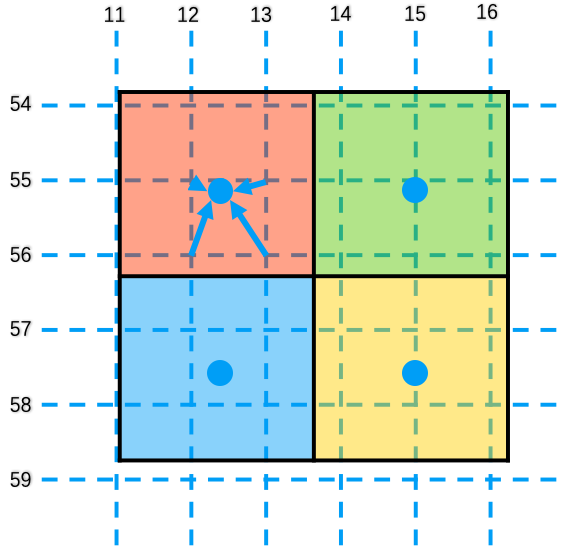
Fig. 10 RoI alignment with output size=(2, 2) and 1 sample point each bin.
It's obvious that one sample point each bin is far from enough in our example. So using more sample points is wiser.
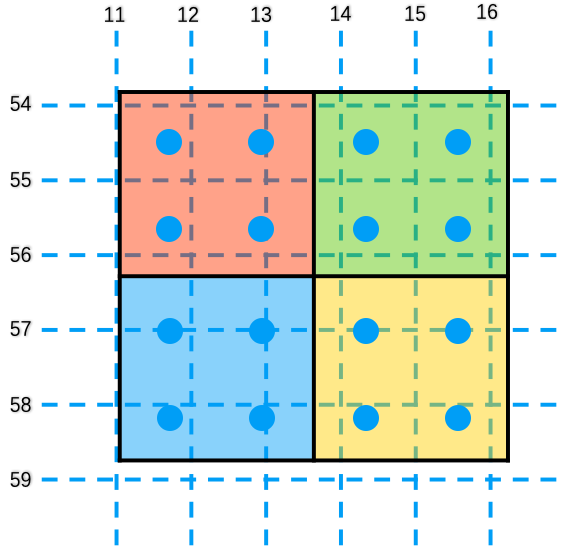
Fig. 11 RoI alignment with output size=(2, 2) and 2×2 sample point each bin.
Contribution
- RoI Align - improving mask accuracy greatly
- Add a segmentation overhead on Faster R-CNN and achieve accurate instance segmentation
6 R-CNNs Proposed by Other Researchers
There are several other R-CNNs by other researchers, which are basically variants of the R-CNN architecture.
Light-Head R-CNN
arXiv: https://arxiv.org/abs/1711.07264
Code(Official, TensorFlow): https://github.com/zengarden/light_head_rcnn
Cascade R-CNN
arXiv: https://arxiv.org/abs/1712.00726
Code(Official, Caffe): https://github.com/zhaoweicai/cascade-rcnn
Code(PyTorch): https://github.com/guoruoqian/cascade-rcnn_Pytorch
Grid R-CNN
arXiv: https://arxiv.org/abs/1811.12030
Code: Not yet
8 References
[10] Xin Lu, et al. "Grid R-CNN." arXiv preprint arXiv:1811.12030 (2018).