从VALSE2019回来后,感觉自己俨然变成了欧阳万里老师的脑残粉呀╰( ᐖ╰)!会上欧阳老师介绍的FishNet简直让我眼前一亮,这么好的点子,我怎么就没想到呐!回来好好读了一下文章和代码,简单总结一下。

从VALSE2019回来后,感觉自己俨然变成了欧阳万里老师的脑残粉呀╰( ᐖ╰)!会上欧阳老师介绍的FishNet简直让我眼前一亮,这么好的点子,我怎么就没想到呐!回来好好读了一下文章和代码,简单总结一下。
The R-CNNs are awesome works on object detection, which demonstrated the effectiveness of using region proposals with deep neural networks, and have become a state-of-the-art baseline for the object detection task. In this blog post I'll make a brief review of the R-CNN family - from R-CNN to Mask R-CNN, and several related works based on the idea of R-CNNs. Implementation and evaluation details are not mentioned here. For those details, please refer to the original papers provided in the References section.
Deep learning researchers have been constructing skyscrapers in recent years. Especially, VGG nets and GoogLeNet have pushed the depths of convolutional networks to the extreme. But questions remain: if time and money aren't problems, are deeper networks always performing better? Not exactly.
When residual networks were proposed, researchers around the world was stunned by its depth. "Jesus Christ! Is this a neural network or the Dubai Tower?" But don't be afraid! These networks are deep but the structures are simple. Interestingly, these networks not only defeated all opponents in the classification, detection, localization challenges in ImageNet 2015, but were also the main innovation in the best paper of CVPR2016.
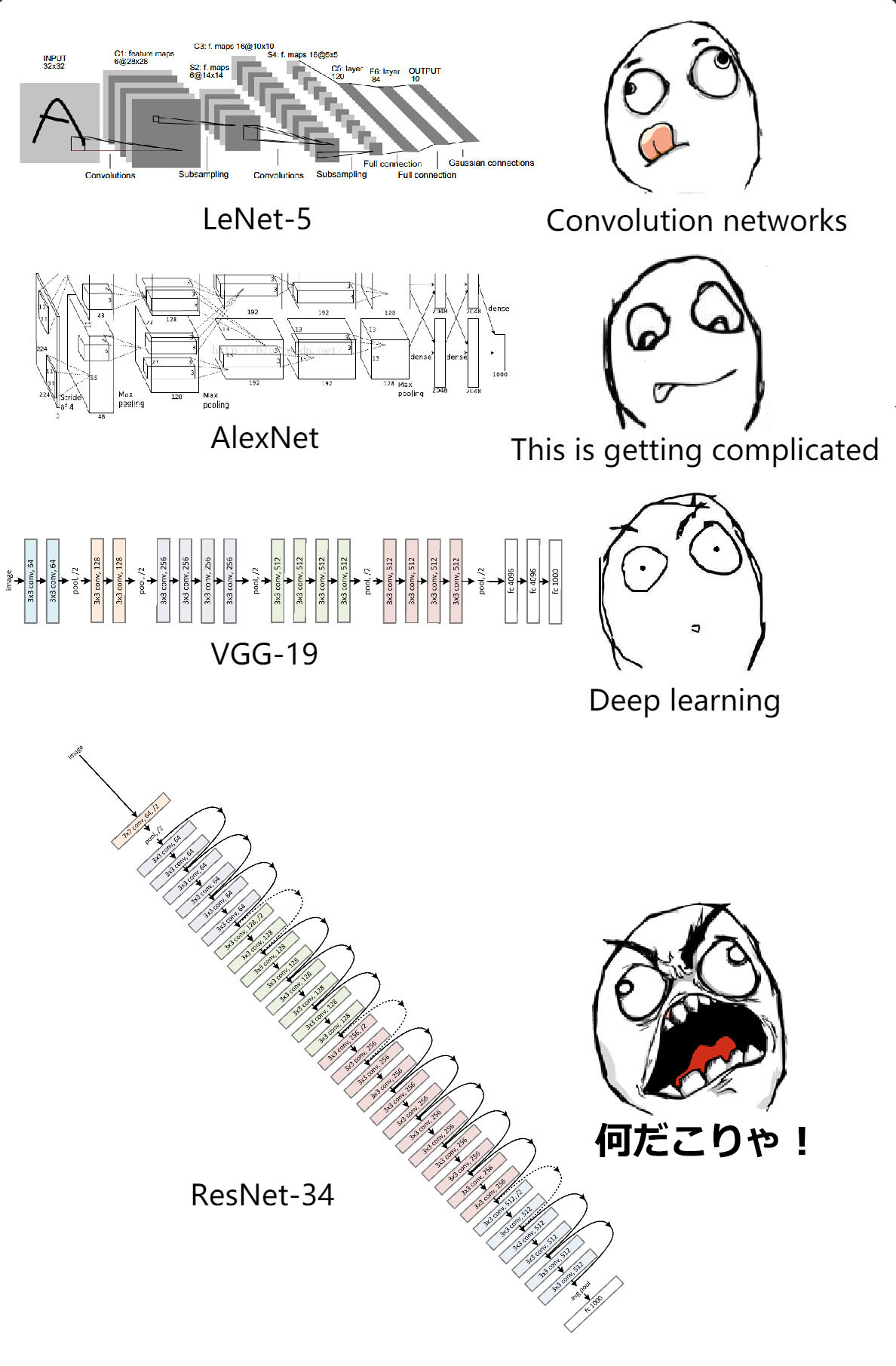
Convolutional neural networks(CNN) have enjoyed great success in computer vision research fields in the past few years. A number of attempts are made based on the original CNN architecture to improve its accuracy and performance. In 2014, Karen Simonyan et al. did an investigation on the effect of depth on CNNs' accuracy in large-scale image recognition (thus also proposing a series of very deep CNNs which are usually called VGG nets). The result confirmed the importance of CNN depth in visual representations.
Before introducing VGG net, let's take a glance at prior convolutional neural networks.
Basic neural network structures(for example, multi-layer perceptron) learn patterns on 1D vectors, which cannot cope with 2D features in images well. In 1986, Lecun et al. proposed a convolution network model called LeNet-5. Its structure is fairly simple: two convolution layers, two subsampling layers and a few fully connected layers. This network was used to solve a number recognition problem. (If you need to learn more about the convolution operation, please refer to Google or Digital Image Processing by Rafael C. Gonzalez)